阿里云毫无疑问是国内最大的主机商,在全球也能排在前5的位置,其规模和可靠性是毋庸置疑的。
现在GPU服务器非常的火,可以用供不应求来形容,广泛应用于AI推理、AI训练、图形视频处理、科学计算、深度学习等领域。但是目前市面上能提供稳定可靠GPU服务器的主机商就那么几家,之前我们推荐的UCloud GPU服务器算一家,阿里云当然也有这个能力。主要原因就是GPU服务器成本比较高,再加上现在英伟达GPU显卡供不应求,造成了价格上的暴涨,带来的成本自然就更高了。

阿里云GPU服务器概要
阿里云提供了弹性计算的GPU云服务器,具体超强的计算能力,非常适合深度学习、科学计算、图形可视化、视频处理等多种应用场景,首次购买优惠力度达到5折,提供英伟达(NVIDIA)V100、A10、P100、P4、T4多种显卡可以选择。
本身阿里云自己的AI发展也是不错的,所以购买他们家的GPU服务器,可以赠送AIACC-Training、AIACC-Inference、FastGPU、cGPU、EAIS多种提高GPU计算效率是软件,大大节约成本。
数据中心
阿里云的GPU服务器有国内和国外多个机房可以选择,国内有北京、青岛、杭州、上海、深圳、成都、香港等,而国外机房包括日本、韩国、新加坡、马来西亚(吉隆坡)、菲律宾(马尼拉)、印尼(雅加达)、泰国(曼谷)、美国(弗吉尼亚、硅谷)、英国(伦敦)、德国(法兰克福)、阿联酋(迪拜)。可以看到节点是非常多的,能够满足全球业务的需求。
价格套餐
阿里云的GPU云服务器提供了按小时付费的套餐,如果你只是想试用一下那么就可以先尝试按小时付款的方式。当然如果是要长期大量使用还是建议开通按月或者按年支付的套餐。
阿里云根据不同的用途提供了不同的GPU云服务器套餐。
特惠套餐
特惠套餐最低价格是1694元/月,有英伟达A10、V100、T4多种显卡可以选,具体套餐如下图所示:
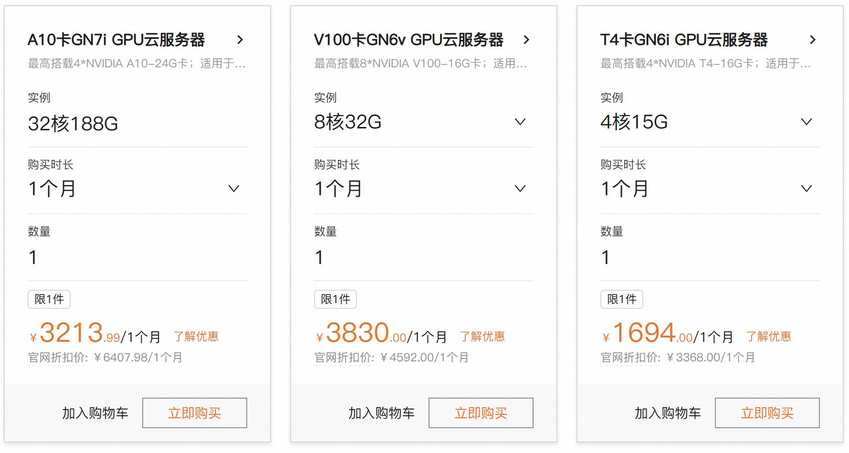
当然这个套餐是会不停变化的,因为优惠活动可能有所不同。
AI推理
AI推理套餐提供了V100、A10、P100、P4多个显卡可以选择,最低价格是1903.5元/月,具体价格套餐如下所示:
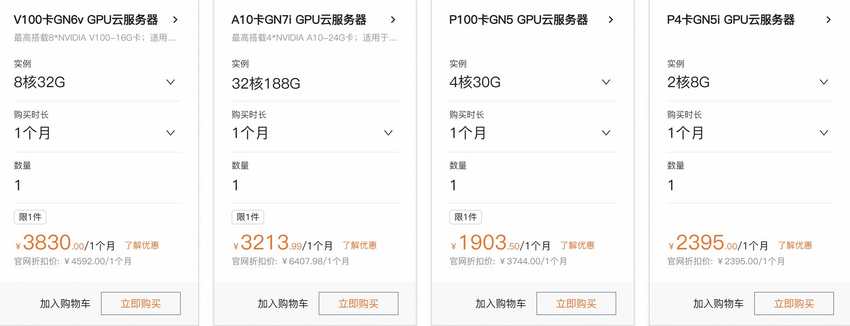
上面也只是最基本的套餐,可以选配到82核、336GB的超高配置,可以配置8颗显卡。
AI训练
AI训练提供了2个大类型的套餐,提供了V100 32G显存的GPU,最低价格是3830元/月,基础套餐如下:
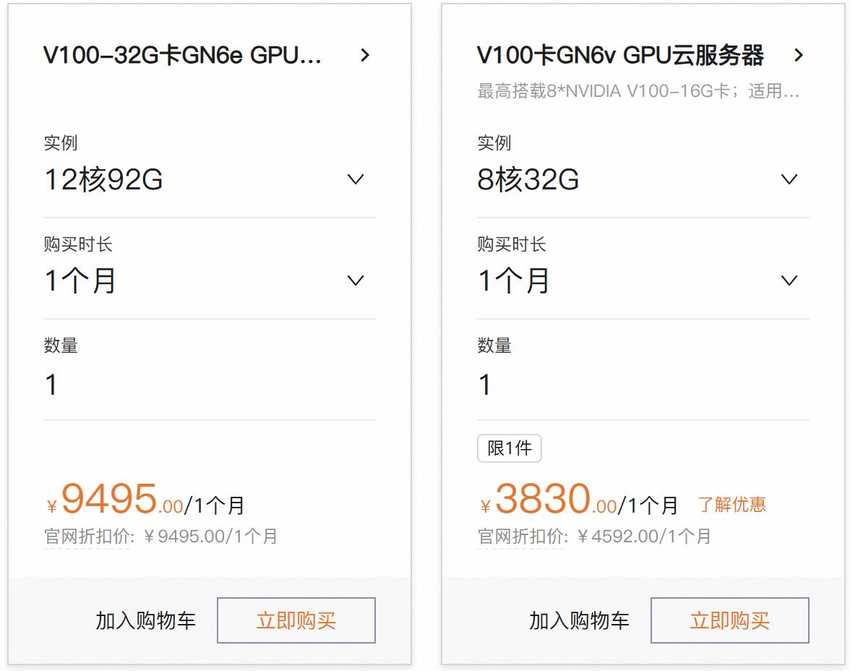
同样可以选配到82核、336GB内存,最高可配置8颗显卡。
图形图像
图形图像处理的套餐主要提供的是英伟达A10、T4显卡,最低价格是1503.5元/月,具体套餐如下所示:
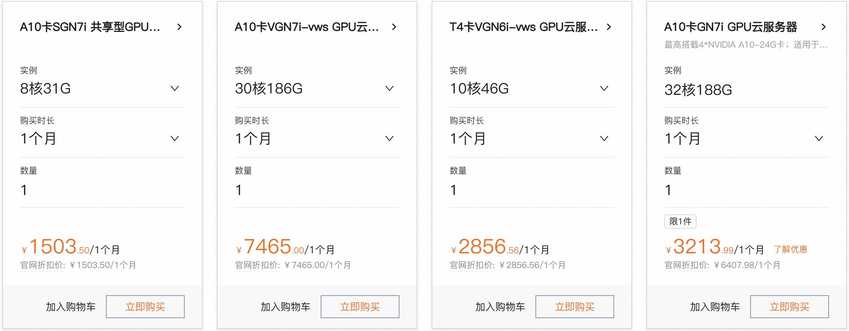
此类型可以提供最高30核、186GB配置,最高搭载4*NVIDIA A10显卡。
科学计算
科学计算类型提供了2种大类型的套餐,主要是V100显卡,最低配置3830元/月,具体套餐如下:
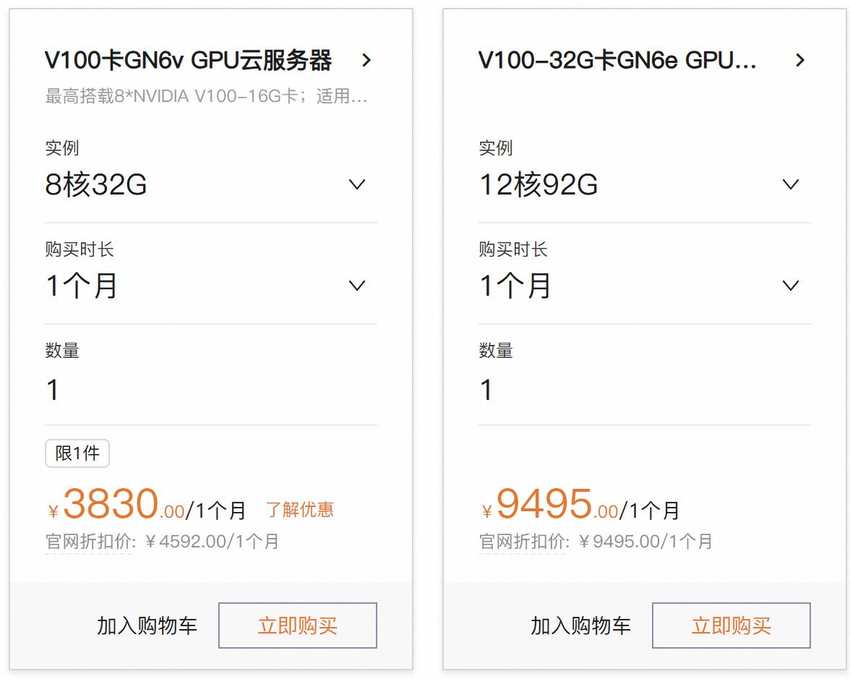
支持82核、336GB内存,最高搭载8*NVIDIA V100-16G卡。
按量付费套餐
除了按月或者按年支付的套餐,阿里云的GPU云服务器还有按小时付款的套餐,最低只需要1.2元/小时,如下所示:

注意的是按量付费套餐,价格要比按月或者按年高很多,建议前期体验的时候购买。
购买教程
阿里云的产品线确实太多了,这里我们简单用图文教程描述下怎么购买GPU云服务器。
首先通过阿里云优惠链接进入官网,选择【产品】>【计算】>【GPU云服务器】链接:
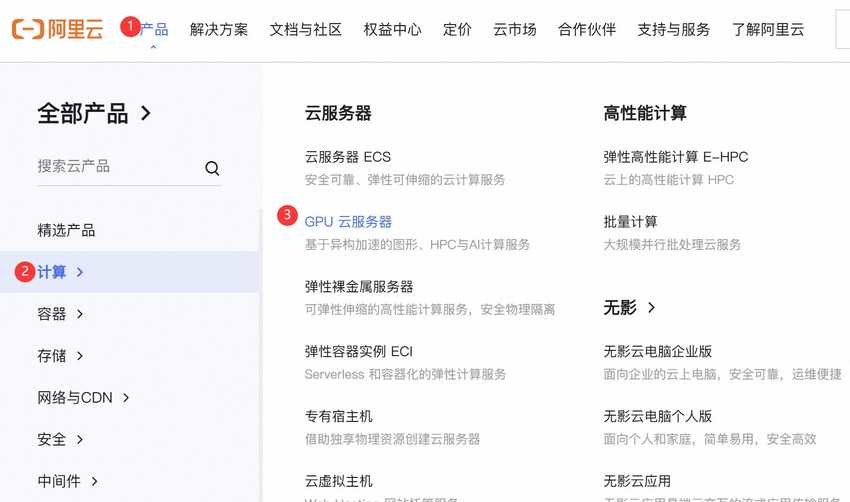
进入GPU服务器产品页面后,点击【立即购买】按钮,选择适合自己的套餐:
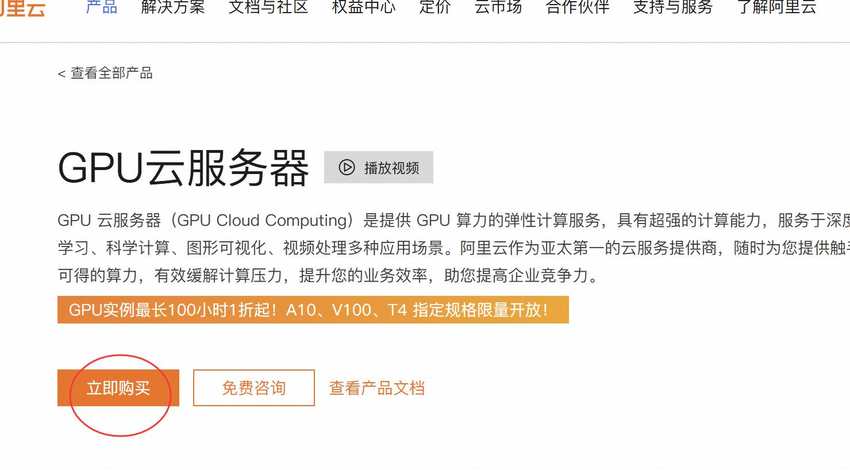
也可以直接在产品页面选择GPU服务器套餐。需要注意的是如果之前没有登录,需要先登录,如果没有账号那么就需要先注册:
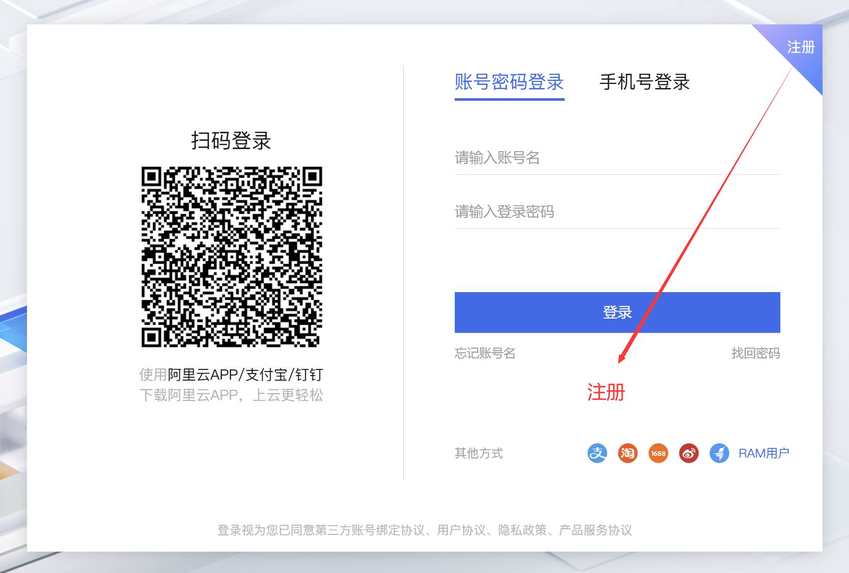
其他的配置按照自己需要选购就可以了,下单后就可以立即部署使用了。
阿里云GPU软件介绍
阿里云的GPU软件为GPU服务器用户提供了众多的方便,并提提升服务器计算能力,下面我们就具体介绍下他们家的GPU软件。
AIACC-Training
AIACC-Training是阿里云匠心打造的神龙AI加速训练引擎,专为阿里云生态系统进行了精密的深度优化,旨在显著增强分布式训练的性能表现,并极大程度地提升网络带宽的有效利用率。迄今为止,这一创新性的AI加速解决方案——AIACC-Training,已在国际舞台上大放异彩,一举夺得两项令人瞩目的世界纪录桂冠:
- 其一,在斯坦福大学著名的Dawnbench基准测试中,神龙AI加速训练引擎以无与伦比的速度,在Imagenet数据集的训练任务上拔得头筹,荣膺全球最快训练速度之誉;
- 其二,同样是在Dawnbench Imagenet训练项目中,该引擎凭借其卓越的能效比,实现了最低的训练成本,再次问鼎世界之巅,彰显了其在成本控制方面的卓越能力。

功能特点如下:
- 支持四种主流框架:Tensorflow, Pytorch, MXNet和Caffe四种分布式训练框架
- 性能提升50%至300%:适用于带宽密度的网络模型
- 单机多卡/多机多卡间高性能通信:支持FP16梯度压缩及混合精度压缩
- MXNet的API扩展:支持insightface类型的数据+模型并行
- RDMA网络深度优化:支持混合链路通信(RDMA+VPC)
AIACC-Inference
阿里云倾力打造的AIACC-Inference,是一款专为神龙架构设计的AI加速推理引擎。该引擎经过对阿里云环境的深度定制与优化,实现了GPU资源的高效利用,显著增强了推理业务的整体性能。截至目前,AIACC-Inference已在国际舞台上大放异彩,连续刷新两项斯坦福Dawnbench Imagenet基准测试的世界纪录:
- 其一,斯坦福Dawnbench Imagenet 推理延迟最低,世界第一
- 其二,斯坦福Dawnbench Imagenet 推理成本最低,世界第一
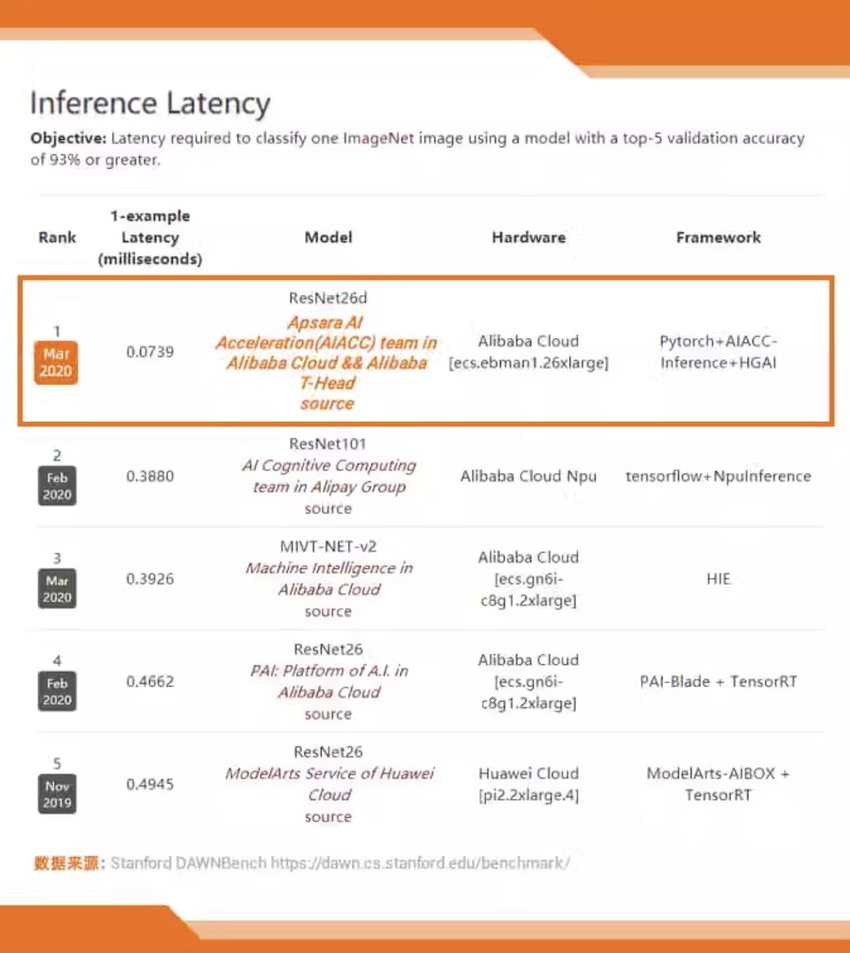
功能特点如下:
- 支持多个框架:Tensorflow, Pytorch, MXNet及其它可导出ONNX模型的深度学习框架进行GPU推理优化
- 性能提升30%至400%:适用于计算密集的网络模型
- 支持两种精度模型:FP32和FP16两种精度的模型优化
FastGPU-GPU实例集群极速部署工具
FastGPU是阿里云专为用户打造的一款GPU实例集群高效部署解决方案。该工具赋能用户,在阿里云平台上实现GPU计算资源的快速一键部署,确保资源的无缝适配与即时运行。通过FastGPU,用户能够享受到前所未有的便捷性,轻松构建起既省时又经济的阿里云GPU实例集群,随时随地满足其计算需求。
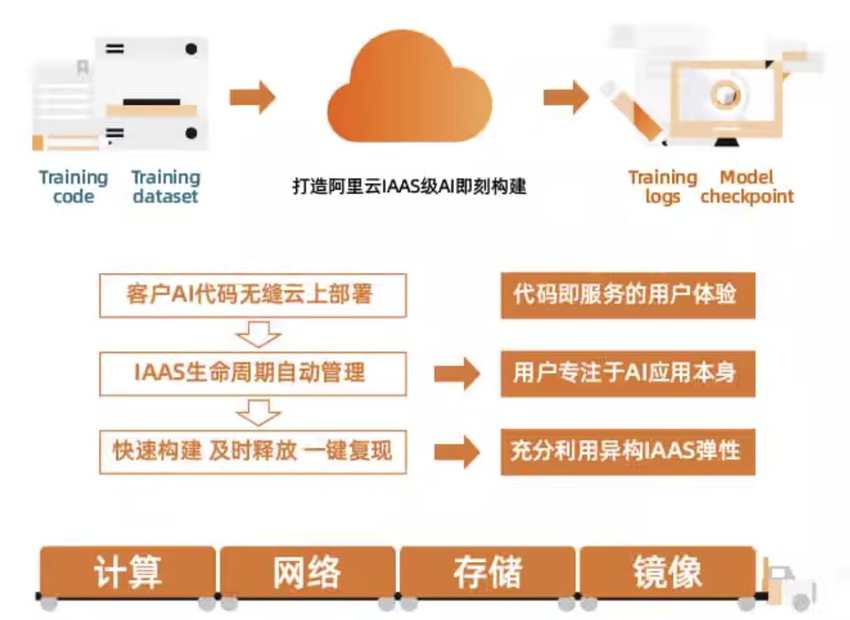
功能特点如下:
- 快速部署:提供便捷的API将线下训练/推理脚本快速部署在阿里云GPU实例集群中
- 便捷管理:提供便捷的命令行工具用于管理阿里云GPU实例集群的运行状态和生命周期
- 高效省时:用户无需进行阿里云IAAS层相关的计算、存储、网络等繁琐的部署操作,获取集群资源时自动获取相应环境
cGPU
cGPU一款创新的软件解决方案,专为在图形处理单元(GPU)上构建并运行多个GPU容器而设计,此方案能够巧妙地将GPU资源进行高效隔离,从而使得单一GPU能够支撑起多个容器的同时运作,实现资源的高度共享。cGPU赋予了单张显卡并行运行多个容器的能力,并且在这些容器之间实施严格的GPU应用隔离策略,极大地促进了GPU硬件资源的优化配置与高效利用。
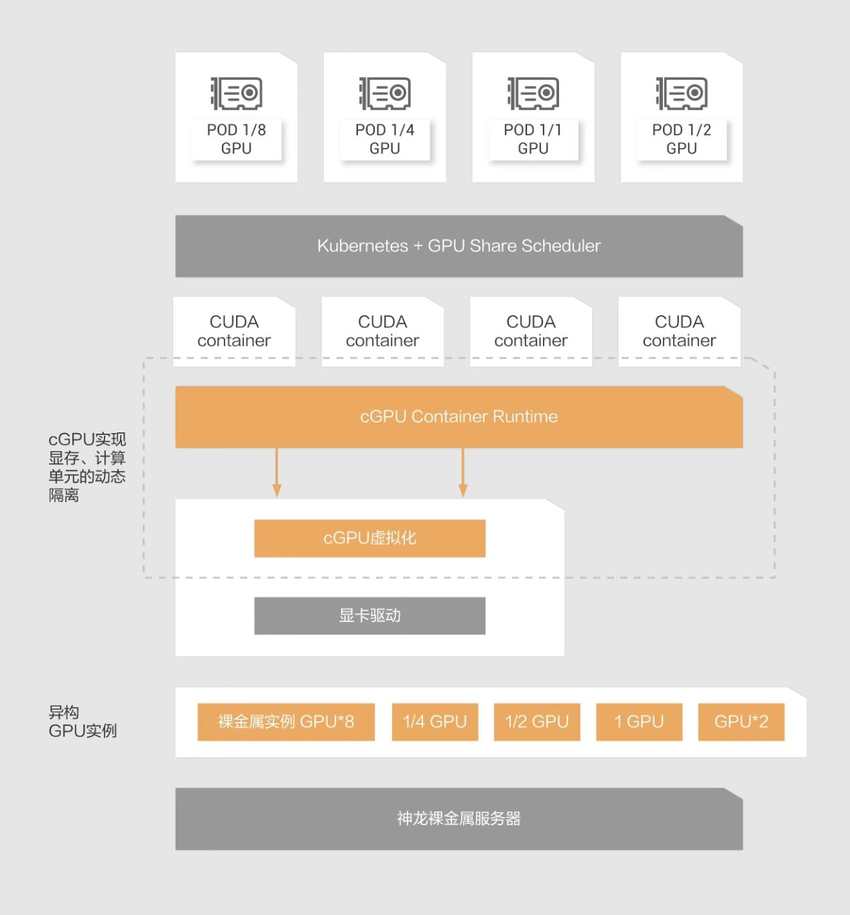
功能特点如下:
- GPU切分:划分GPU提升GPU利用率
- 共享GPU:多个AI应用共享GPU节约成本
- 灵活匹配:算力和显存灵活切分,满足应用需求
EAIS
EAIS这是一款专为Alibaba ECS实例设计的灵活解决方案,可通过添加GPU加速资源来提升性能。你可以在Alibaba 服务器上根据你的应用程序的整体计算和内存需求,选择最合适的ECS实例,然后配置所需级别的GPU驱动推理加速。这种方法不仅能最大限度地利用资源,还能迅速实现高达50%的成本节约。
功能特点如下:
- 推理成本降低50%:满足用户选择最合适应用的ECS总体计算实例类型,单独制定所需GPU推理加速量级,相比GPU推理实例成本降低50%
- 灵活的CPU与GPU配比:根据用户需求灵活配比CPU和GPU资源,准确获取用户需求
- 弹性伸缩:轻松扩展和缩减推理加速量级,有助于用户仅为所需资源付费
总结
以上就是关于阿里云GPU云服务器的介绍,可以说功能是非常强大的,类型非常的多,能够满足AI推理、深度学习、图形视频处理等多个领域的用途。
阿里云的GPU云服务器提供了多种计费方式,按小时、按月、按年都支持,便捷灵活,满足众多用户需求。
除此之外就是阿里云的GPU云服务网器提供了众多的辅助软件支持,让你在搭建环境上能够节约不少的时间,并且提供了计算效率提升软件,让你能够节约大量计算成本。